728x90
2007년부터 2011년도까지 중국, EU, 미국, 일본, 한국, 멕시코 등의 주요 자동차 생산 대수가 백만대 단위로 저장된 데이터를 활용할 예정 (DataFrame)
path = 'https://github.com/dongupak/DataML/raw/main/csv/'
file = path + 'vehicle_prod.csv'
1. 데이터프레임 시각화
특정한 열 하나를 보기위해선 DataFrame['칼럼 이름']을 통해 보았고, 여러 열을 보기위해선 [['칼럼1', '칼럼2', '칼럼3']]과 같이 이중 대괄호를 사용해 보았다.
판다스는 시각화 메소드 plot()메소드를 사용할 수 있다. ( bar, pie, line 등)
df4 = pd.read_csv(file, index_col = 0)
df4['2009'].plot(kind='bar', color=('r','g','b','c','k','orange'))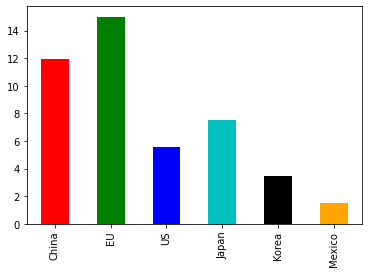
df4['2011'].plot(kind='pie')
df4.plot.line()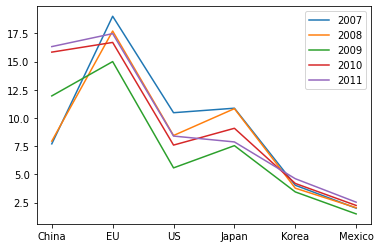
2007년부터 2011년까지 나라별 자동차 생산 대수를 그래프로 확인하고 싶을 때 이 방법은 좋은 방법은 아니라고 생각한다.
df4.plot.bar()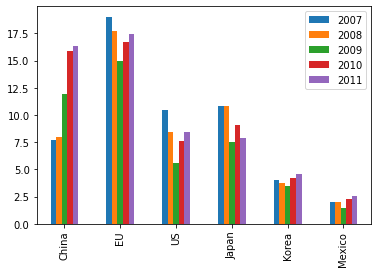
t1 = df4.T # 행과 열의 위치를 바꿔줌 transpose()
t1.plot.line()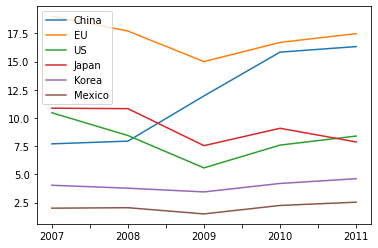
df4.T 또는 df4.transpose() 메소드를 통해 데이터프레임의 인덱스와 컬럼의 위치를 바꿀 수 있다.
그 결과 나머지 그래프들 보다 가독성 좋은 그래프가 나온다.
( 중국의 자동차 생산량이 매년 가파르게 증가하고 있으며, 일본의 경우 감소하는 것을 이해할 수 있다.)
728x90
'DATA > Pandas' 카테고리의 다른 글
| Pandas - 시계열 자료 분석 DatetimeIndex (0) | 2022.12.06 |
|---|---|
| Pandas - 데이터 정제와 결손값 처리 (0) | 2022.12.06 |
| Pandas - 인덱싱과 슬라이싱 ( head, tail, loc, iloc ) (1) | 2022.11.27 |
| Pandas - csv, DataFrame 구조, 열 생성과 삭제 (0) | 2022.11.27 |
| Pandas - 기초, Serise, DataFrame, isna() (0) | 2022.11.27 |



